技术
在2015年11月9号Google发布了人工智能系统TensorFlow并宣布开源,此举在深度学习领域影响巨大,也受到大量的深度学习开发者极大的关注。当然,对于人工智能这个领域,依然有不少质疑的声音,但不可否认的是人工智能仍然是未来发展的趋势。
而TensorFlow能够在登陆GitHub的当天就成为最受关注的项目,作为构建深度学习模型的最佳方式、深度学习框架的领头者,在发布当周轻松获得超过1万个星数评级,这主要是因为Google在人工智能领域的研发成绩斐然和神级的技术人才储备。当然还有一点是在围棋上第一次打败人类,然后升级版Master保持连续60盘不败的AlphaGo,其强化学习的框架也是基于TensorFlow的高级API实现的。
作为Goolge二代DL框架,使用数据流图的形式进行计算的TensorFlow已经成为了机器学习、深度学习领域中最受欢迎的框架之一。自从发布以来,TensorFlow不断在完善并增加新功能,并在今年的2月26号在Mountain View举办的首届年度TensorFlow开发者峰会上正式发布了TensorFlow 1.0版本,其最大的亮点就是通过优化模型达到最快的速度,且快到令人难以置信,更让人想不到的是很多拥护者用TensorFlow 1.0的发布来定义AI的元年。
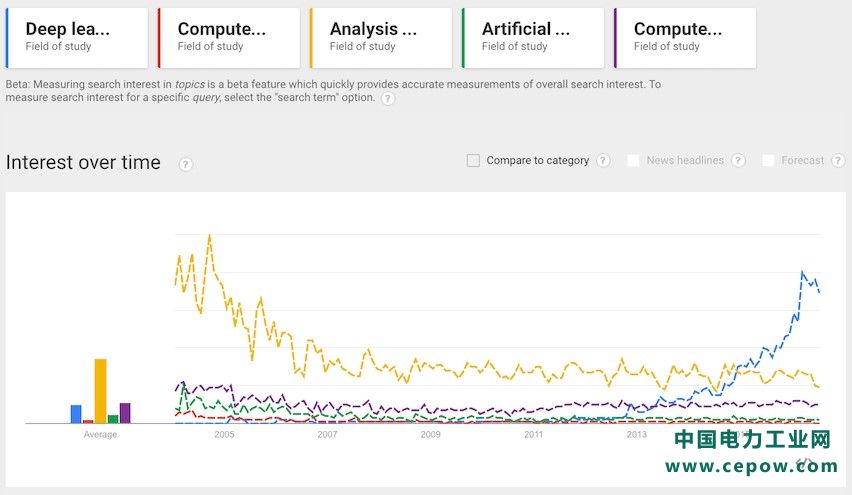
通过以上Google指数,深度学习占据目前流程技术的第一位
TensorFlow在过去获得成绩主要有以下几点:
|
Google第一代分布式机器学习框架DistBelief不再满足Google内部的需求,Google的小伙伴们在DistBelief基础上做了重新设计,引入各种计算设备的支持包括CPU/GPU/TPU,以及能够很好地运行在移动端,如安卓设备、ios、树莓派 等等,支持多种不同的语言(因为各种high-level的api,训练仅支持Python,inference支持包括C++,Go,Java等等),另外包括像TensorBoard这类很棒的工具,能够有效地提高深度学习研究工作者的效率。
TensorFlow在Google内部项目应用的增长也十分迅速:在Google多个产品都有应用如:Gmail,Google Play Recommendation, Search, Translate, Map等等;有将近100多project和paper使用TensorFlow做相关工作。

TensorFlow在正式版发布前的过去14个月的时间内也获得了很多的成绩,包括475+非Google的Contributors,14000+次commit,超过5500标题中出现过TensorFlow的github project以及在Stack Overflow上有包括5000+个已被回答 的问题,平均每周80+的issue提交,且被一些顶尖的学术研究项目使用: – Neural Machine Translation – Neural Architecture Search – Show and Tell.
当然了,说到底深度学习就是用非监督式或者半监督式的特征学习,分层特征提取高校算法来替代手工获取特征。目前研究人员和从事深度学习的开发者使用深度学习框架也并非只有TensorFlow一个,同样也有很多在视觉、语言、自然语言处理和生物信息等领域较为优秀的框架,比如Torch、Caffe、Theano、Deeplearning4j等。
下面,编者整理段石石博文中的一些对网络神经模型、算法深度分析的内容,了解TensorFlow这个开源深度学习框架的强大之处。
这篇文章主要针对Tensorflow利用CNN的方法对艺术照片做下Neural Style的相关工作。首先,作者会详细解释下A Neural Algorithm of Artistic Style这篇paper是怎么做的,然后会结合一个开源的Tensorflow的Neural Style版本来领略下大神的风采。
A Neural Algorithm of Artistic Style
在艺术领域,尤其是绘画,艺术家们通过创造不同的内容与风格,并相互交融影响来创立独立的视觉体验。如果给定两张图像,现在的技术手段,完全有能力让计算机识别出图像具体内容。而风格是一种很抽象的东西,在计算机的眼中,当然就是一些pixel,但人眼就能很有效地的辨别出不同画家不同的style,是否有一些更复杂的feature来构成,最开始学习DeepLearning的paper时,多层网络的实质其实就是找出更复杂、更内在的features,所以图像的style理论上可以通过多层网络来提取里面可能一些有意思的东西。而这篇文章就是利用卷积神经网络(利用pretrain的Pre-trained VGG network model)来分别做Content、Style的reconstruction,在合成时考虑content loss 与style loss的最小化(其实还包括去噪变化的的loss),这样合成出来的图像会保证在content 和style的重构上更准确。

这里是整个paper在neural style的工作流,理解这幅图对理解整篇paper的逻辑很关键,主要分为两部分:
|
理解了以上两点,剩下的就是建模的数据问题了,这里按Content和Style来分别计算loss,Content loss的method比较简单:
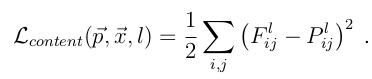

其中F^l是产生的Content Representation在第l层的数据表示,P^l是原始图片在第l层的数据表示,定义squared-error loss为两种特征表示的error。
Style的loss基本也和Content loss一样,只不过要包含每一层输出的errors之和
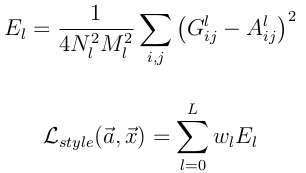

其中A^l 是原始style图片在第l的数据表示,而G^l是产生的Style Representation在第l层的表示
定义好loss之后就是采用优化方法来最小化模型loss(注意paper当中只有content loss和style loss),源码当中还涉及到降噪的loss:
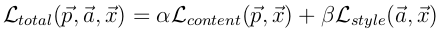

优化方法这里就不讲了,tensorflow有内置的如Adam这样的方法来处理。
前面看了一些Tensorflow的文档和一些比较有意思的项目,发现这里面水很深的,需要多花时间好好从头了解下,尤其是cv这块的东西,特别感兴趣,接下来一段时间会开始深入了解ImageNet比赛中中获得好成绩的那些模型: AlexNet、GoogLeNet、VGG(对就是之前在nerual network用的pretrained的model)、deep residual networks。
ImageNet Classification with Deep Convolutional Neural Networks
ImageNet Classification with Deep Convolutional Neural Networks 是Hinton和他的学生Alex Krizhevsky在12年ImageNet Challenge使用的模型结构,刷新了Image Classification的几率,从此deep learning在Image这块开始一次次超过state-of-art,甚至于搭到打败人类的地步,看这边文章的过程中,发现了很多以前零零散散看到的一些优化技术,但是很多没有深入了解,这篇文章讲解了他们alexnet如何做到能达到那么好的成绩,好的废话不多说,来开始看文章:
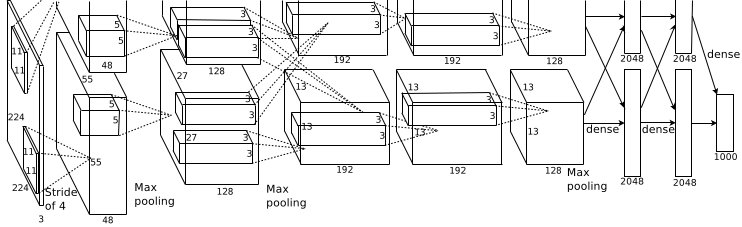
这张图是基本的caffe中alexnet的网络结构,这里比较抽象,作者用caffe的draw_net把alexnet的网络结构画出来了:
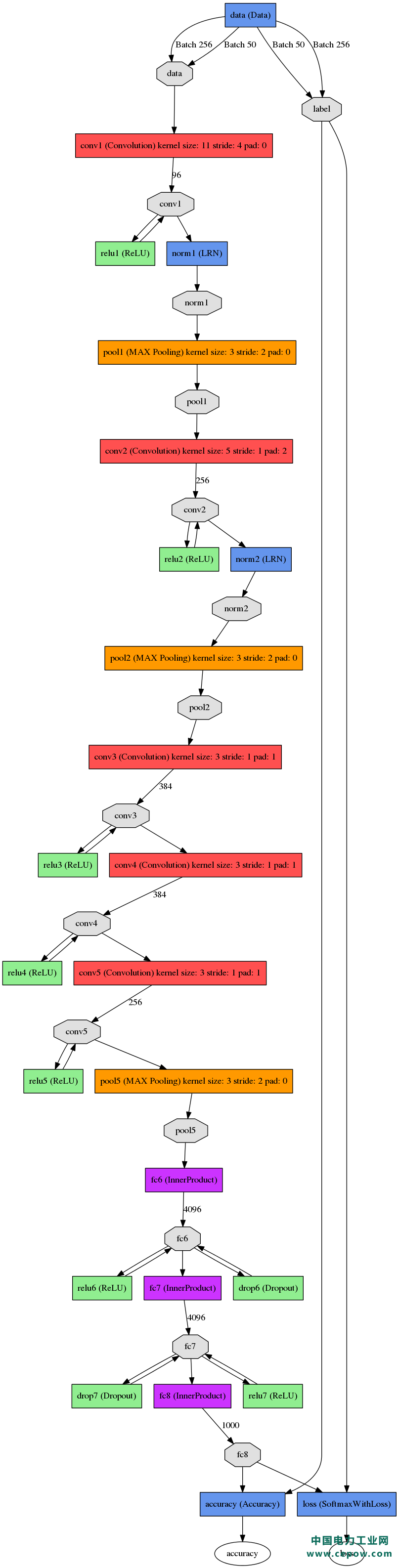
alexnet总共包括8层,其中前5层convolutional,后面3层是full-connected,文章里面说的是减少任何一个卷积结果会变得很差,下面具体讲讲每一层的构成:
|