技术
在阿里巴巴集团首席安全专家杜跃进看来,随着人脸识别、指纹解锁、虹膜比对等生物特征识别技术在日常生活中的广泛使用,个人隐私的泄露方式也开始变得多样。
 用Python实现一个大数据搜索引擎
用Python实现一个大数据搜索引擎
搜索是大数据领域里常见的需求。Splunk和ELK分别是该领域在非开源和开源领域里的领导者。布隆过滤器是大数据领域的一个常见算法,它的目的是过滤掉那些不是目标的元素。
和其他数据库开发者一样,Stonebraker 也读了 IBMer Edgar Codd 的早期关系数据模型论文。从1973年开始,在IBM System R 数据库的基础上 Stonebraker 开始了 Ingres 数据库的工作。
 OpenTSDB在HBase上的优化及HiTSDB的优化和提高
OpenTSDB在HBase上的优化及HiTSDB的优化和提高
本文主要从时序数据开始介绍,包括时序序列数据的特点,接着介绍了时序数据业务场景,以及OpenTSDB在HBase上的优化,最后分享了HiTSDB的优化和提高。
 OpenStack与Kubernetes融合
OpenStack与Kubernetes融合
在Kubernetes架构下,提供docker容器网络与周期管理。通过COE(Container Orchestration Engine)管理的容器群,不但享受便利,也拥有快速编排应用程序架构的优势。
 ACI是什么?微软Azure容器实例解析
ACI是什么?微软Azure容器实例解析
作为一类新型云平台,Azure容器实例(简称ACI)是一项“容器即服务”方案,允许大家在无需承担日常开销且可运用脚本化命令集的前提下,快速创建并启动容器化应用程序。
 大数据是科学家很难攻破的一道题
大数据是科学家很难攻破的一道题
和 Hadoop 一样,Spark 提供了一个 Map Reduce API(分布式计算)和分布式存储。二者主要的不同点是,Spark 在集群的内存中保存数据,
 聊聊MapReduce处理过程中的数据类型与数据格式
聊聊MapReduce处理过程中的数据类型与数据格式
MapReduce处理过程总览对于MP的处理过程我想大部分人都已经知道了其原理,思路不难,这是肯定的,但是整个过程中需要考虑的细枝末节的点还
 在 Apache Hive 中轻松生存的12个技巧
在 Apache Hive 中轻松生存的12个技巧
Hive 可以让你在 Hadoop 上使用 SQL,但是在分布式系统上优化 SQL 则有所不同。这里是让你可以轻松驾驭 Hive 的12个技巧。Hive 并
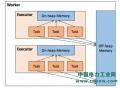 Apache Spark 内存管理详解
Apache Spark 内存管理详解
Spark 作为一个基于内存的分布式计算引擎,其内存管理模块在整个系统中扮演着非常重要的角色。理解 Spark 内存管理的基本原理,有助于更
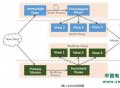 Kappa:比Lambda更好更灵活的实时处理架构
Kappa:比Lambda更好更灵活的实时处理架构
本篇文章中分析Lambda三层结构模型的适用场景,同时暴露出Lambda架构一个最明显的问题:它需要维护两套分别跑在批处理和实时计算系统上面的