技术
调优1:开启convergence模式
若你的OpenStack环境已经到了Mitaka或是以上版本。则建议你将convergence模式打开(若版本为Newton以上版本,预设已经是开启)。打开方式为在`/etc/heat/heat.conf`档案下加入`convergence_engine = True`的选项。
开启后对于操作不会有任何改变,使用者仍可以用原先的操作模式与脚本建立编排资源。原先已经建立的编排资源则会维持在非Convergence模式下继续运行。而新建立的编排资源则会以Convergence模式维运。
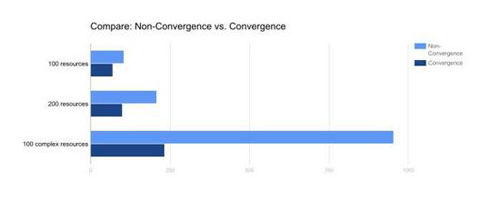
下图为比较建立100个简单的资源,200个简单的资源,与100个复杂资源时在Convergence模式或是非Convergence模式下的效能。可以观察到,越复杂的资源越需要更多的时间来完成,越容易在Convergence模式下获得大幅的改善。
尤其是针对像是Kubernetes等需要建立多台Nova Instance (虚拟机或裸机)的状况下,通过模式转换而获得的效率改善理应更显著(Kubernetes一般架构属于复杂度较高的资源,因此可以参考图中复杂度高的状况比较表)。
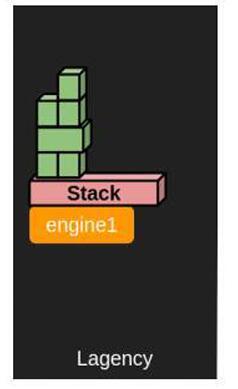
什么是Convergence模式?
谈到这里,应该有不少开发者对Convergence相当陌生。 Convergence比起旧架构在服务之间的差异只有新增了一个worker服务。但是实际上程序流程完全不同。如果我们如下指令建立一个Kubernetes 群集。

如果是旧有的架构指令会被转为API call,再通过RPC交由其中的一个后端Engine服务由头到尾处理整个Kubernetes资源建构。
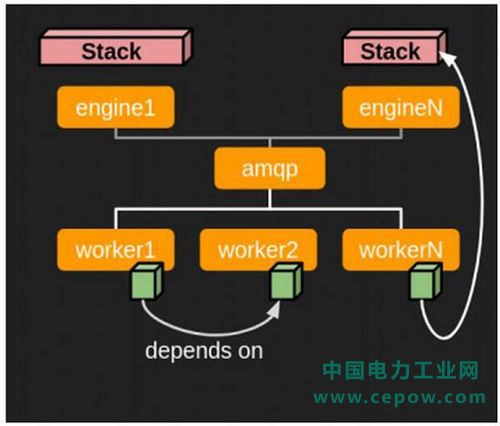
但如下图在Convergence模式下,Kubernetes脚本抵达后端服务(Engine)时,会依照资源立刻被分成单一工作,交付给其他后端服务并行执行。
也就是说,若后端服务数量允许,所有的Kubernetes master与minion都可以并行运行在独立的后端服务,并且只需要你花费部署一台节点的时间,就可以将整个集群都建置完毕。
过程中Heat服务会在数据库中建立一张叫做Syncpoint的表,用来确认与取得操作的权限。并且存入资源相依性的连结数据以保证有资源创建流程(像是确保Cinder Volume挂载操作,必须在Nova将Kubernetes节点与Cinder Volume创建出来后才能执行)。
调优2:调整`num_engine_workers`
Engine worker数量调整,指的就是我们在调优1时提及的后端服务数量。通过下图架构可以看到,当API服务收到请求,并通过RPC往后方传送时,是在多个Engine worker中,由抢先接收到者,作为处理该请求的后端。
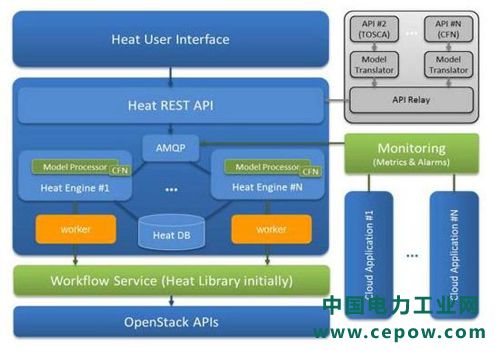
而这个调优设定可以用来决定每一个实体的Heat后端节点上要跑几个后端服务程序。如若环境(在`/etc/heat/heat.conf`文件)尚未设定此参数,预设是按照CPU数量来调整单一节点上Heat的服务程序数量。
但是注意到,若你的电脑为HPC时建议将数量调高,因为你拥有较为强大的网络、运算、与储存资源,可以尝试由1:1.5(cpu:num_engine_workers)开始测试效能,在往上调整,直到你的Kubernetes集群的布署效能达到顶峰。
相对地,若你的CPU数量过多,其他部分的资源并未规划为高效能状况(可能发生在用来提供运算的节点上),建议尝试1.25:1(cpu:num_engine_workers)开始测试效能,并往下调整(num_engine_workers数量),直到你的环境取得更好的整体效能。
注意到单一节点上的编排服务程序数量,并不等于多节点上的整合。因此调整到适当的数量,也等同于提供其他程序(RPC、数据库、其他服务程序)更多资源的使用空间。
尤其是像布署Kubernetes环境,将会同时调用Cinder管理储存, Neutron管理网络Nova管理虚机或裸机。因此资源分配更应该微调以获取更好的整体效能。
调优3:开启高速缓存
多数的OpenStack服务都具有一定数量的缓存机制,若内存空间允许建议挑选部分服务(比如编排服务)开启缓存机制,开启方式为将缓存设定写入heat.conf内。
至于写入选项可参考网站:https:// docs .openstack.org/developer/oslo.cache/opts.html 。若无特别想设定的参数,可以直接在[cache]下新增enabled=True即可。
至于为什么在此特别提及此设定,因为当你要布署或是扩展你的Kubernetes集群时,在资源编排上都会是以资源群组为单位,比如说要再扩展出新的50台Kubernetes minion节点。
在资源编排时,这50台属于同一Kubernetes丛集的minion节点将会被视为同一个资源群集,并在编排时一同处理。因此若能将高速缓存开启,在这案例上就可以直接节省49次等同于98%的部分操作。
目前在编排服务内,以下几个主要环节已经设有快取机制,包含Stack信息数据,Resource信息数据,Constraint数据(通过呼叫其他项目CLI以认证部分参数。例如当K8S master参数有Floating ip时,Constraint就会通过Neutron CLI找寻Floating ip数据作为参数认证依据)等。
调优4:允许OpenStack直接操作Kubernetes
在实际使用Kubernetes时,许多时候需要临时或一次性变更多个 Kubernetes集群,或是对单一个大型的Kubernetes集群进行多次操作或复杂操作,其实也可以纳入OpenStack管理范围作一次性操作,进而完成所有任务。
在编排服务中有能安装与管理应用程序的能力,在提供镜像时,只需要在里面多加入kubelet hook就可以了。后续只需通过更改编排脚本即可进行操作。
对于不知道hook是什么的读者,可以理解基本上它就是一个在os-collect-config协助将文件(例如yaml文件)转入Kubernetes节点上之后,通过节点上kubelet指令执行操作。流程如下图所示:
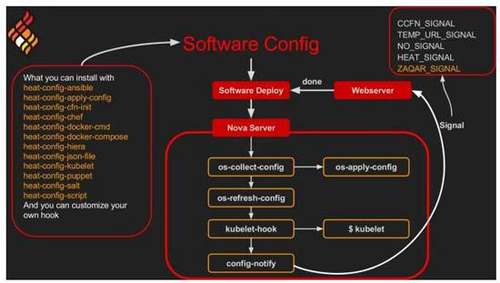
当你计划开发Kubernetes自动化管理时,除了将kubelet hook加入镜像内,也要注意到kubelet执行后,必须要能够发送消息给Heat或Zaqar等等(看你在编排脚本撰写时的设定),因此请务必打开部分防火墙设定(像是80或8080等等)允许消息发送。