技术
HBaseCon是Apache HBase官方举办的技术会议,主要目的是分享,交流HBase这个开源分布式大数据存储的使用和开发以及发展。HBaseCon发起于2012年。通常HBaseCon的举办地是在美国,这是HBaseCon第一次在亚洲举行,命名为Apache HBaseCon 2017 Asia。而且这次会议举办地选择在中国深圳,也足以见得HBase在中国的火爆程度和中国开发者们对HBase社区所做的卓越贡献。

Apache HBase是基于Apache Hadoop构建的一个分布式、可伸缩的Key-Value数据库,它提供了大数据背景下的高性能的随机读写能力。做为最早研究、使用和二次开发HBase技术的中国公司,阿里巴巴从2010年就开始使用HBase,经过近7年的发展,现在采用HBase存储的业务已经超过1000+,拥有了上万台的HBase集群规模,在HBase上存储的数据已达PB级。秉承开源和分享的精神,阿里把HBase的实践经验和改进不断回馈HBase社区,比如说Bucket Cache和Reverse Scan等功能,给HBase技术发展带来了非常深远的影响。同时,也给HBase社区培养了2名PMC和2名Committer,阿里在HBase社区的影响力可见一斑。那么这次HBaseCon 2017 Asia。阿里派出了一位HBase PMC和2位Committer,还有两位资深的HBase开发,给大家带来了十足的干货。
阿里干货系列
一、强同步复制
传统的HBase主备集群同步使用的方案是异步复制,这使得主备集群数据之间会有短暂的数据不同步现象。用户为了灾备,不得不放弃强一致模型。没法放弃强一致语义的用户,必须自己写一套复杂的逻辑来保证主备集群之间数据的读写一致性。阿里的HBase技术专家天引,在此次的HBaseCon Asia上给大家带来了强同步复制方案。

据天引介绍,强同步复制方案采用了主备并发写和RemoteLog技术,使得在同城网络条件下同步复制相对于异步复制仅有2%的吞吐量下降。当一个请求到达主库后,并发写本地和备库,到达备库的同步写不需要走完整的写入路径,而是直接写入RemoteLog,降低同步写开销与延时。除了同步链路外,还有一套异步链路将数据从主库复制到备库,因此正常情况下不需要回放RemoteLog的数据到备库,在主库不可服务的情况下,只需要回放RemoteLog中那些还没有被异步复制链路同步到备库的数据,异步复制只有几秒钟的数据延迟,这保证了可以在很短的时间内完成从主库到备库的切换。
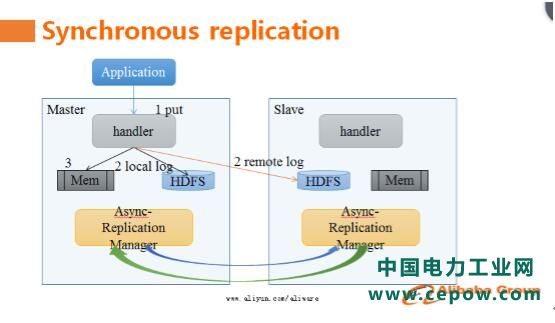
此方案在大会现场引起了强烈反响,很多HBase用户表示这是他们期待已久的功能,希望能尽快使用上。天引表示此功能目前基于阿里内部分支实现、运行及完善,未来将会回馈给社区。
二、SQL on HBase
阿里HBase服务了大量的内部用户,并持续有新用户接入。但是使用HBase的用户有很大一部分是从传统的SQL数据库转过来的,HBase的rowkey设计和API的使用习惯对于他们来说并不友好。为了降低这些转型用户的使用门槛,阿里在HBase上引入了SQL层。来自阿里的资深HBase开发工程师天穆,给大家详细讲解了如何玩转SQL on HBase。

通过优化,现在在阿里使用SQL访问HBase和原生API的速度已经相差无几,而且在SQL语法上,创造性地支持HBase多版本和时间戳等NoSQL才具有的功能。