技术
第三个例子,如果你是做一个实时的日志处理,实时收集所有日志,并将其导入 root,在这种情况下,你可能会说,为了降低成本,我愿意付出一小部分正确性的代价,即使不能达到 100%、达到 99.99%、达到 99.9%,这样的结果都可以接受。这本是用户在定义不同流处理应用或者业务的时候应该可以自己做出的选择。但比较遗憾的是,多数早期的流处理平台其实并没有给予用户该种选择,他们自身的设计理念,那就是为了低延迟直接放弃掉正确性,或者说为了更高的吞吐量直接放弃低延迟。
以上是我想分享的关于流处理的一些误会认知,如果我的分享能够让大家带走两个答案的话,我希望这就是一个。我认为流处理仅仅是一种不一样的计算模型或者编程模型,它将计算带到数据上,而不是将数据引用到计算上,并且在流处理的时候,用户往往需要在正确性、延迟性、成本等不同的维度上做出选择。
Kafka 的角色
为什么当我们说到流处理的时候,很多人都在说 Kafka。大多数人在最早接触 Kafka 时会说,Kafka 就是一个分布式发布订阅的消息系统,但是如果我们去观察 Kafka 的最初一些设计特性可发现以下几点内容。第一点,它可以作为一个写在磁盘上的缓存来使用,或者说,并不是仅基于内存来存储流数据,它可以保证数据包不被及时消费时,依然可用且不被丢失;第二点,由于位移的存在提供了逻辑上的顺序,在同一个话题上,第一个数据比第二个数据最先被发布的时候,也可保证在消费时也是永远第一个数据比第二个数据先被消费;第三点,因为 Kafka 是一个公有的大数据中转站,就是说,所有的数据只要在 Kafka 上,永远可以在 Kafka 周围进行业务的开发或者认知事物的开发。接下来我将花费一些时间详细介绍这三点之间的关系。
Kafka 不仅仅是一个订阅消息系统,同时也是一个大规模的流数据平台,那么它提供了什么呢?第一,提供订阅和发布消息;第二,提供一个缓存的流数据存储平台;第三,提供流数据的处理平台。今天,我将着重讨论流式计算在 Kafka 上面的应用。
流式计算在 Kafka 上的应用主要有哪些选项呢?第一个选项就是 DIY,Kafka 提供了两个客户端 —— 一个简单的发布者和一个简单的消费者,我们可以使用这两个客户端进行简单的流处理操作。举个简单的例子,利用消息消费者来实时消费数据,每当得到新的消费数据时,可做一些计算的结果,再通过数据发布者发布到 Kafka 上,或者将它存储到第三方存储系统中。DIY 的流处理需要成本。打个比方,考虑数据的延迟性,考虑不同时间上的管理分配,正如很多人提到的 processing time,这将是我后文会重点提及的概念。以上这些都说明,利用 DIY 做流处理任务、或者做流处理业务的应用都不是非常简单的一件事情。
第二个选项是进行开源、闭源的流处理平台。比如,spark。关于流处理平台的一个公有认知的表示是,如果你想进行流处理操作,首先拿出一个集群,且该集群包含所有必需内容,比如,如果你要用 spark,那么必须用 spark 的 runtime。因为他们划定了你作为一个流处理平台使用者需要用到的所有行为,比如,资源管理系统、参数调配系统、容器配置、代码封装、分发等,以上行为都已被该平台所限定。一旦你选择使用甲就必须用甲套餐装备,如果选择使用乙就必须使用乙套餐装备。有人不禁提出疑问,我能不能既选择流处理平台,又使用自己选择的,我能不能这样做呢?
这个应用场景其实很普遍,举个例子,可异步式微服务处理。什么叫异步式微服务处理?假设 Kafka 作为一个缓存数据,在该缓存区含有很多不同的业务。打个比方,一个网店的机构可以有不同的组、不同的员工,有人负责销售、有人负责商品分发,有人负责价格管理、有人负责在线实时的限流监控,不同的组、不同的员工可能会以不同的时间,或者以不同的代码来更新他们的产品,只要拥有一个异步式缓存机制,即 Kafka,便可扩大该微服务,而不需要他们的任何一个组之间进行同步请求应答机制。
在该微服务情况下,每个小组的喜好、特性并不一致,有的组表示我需要做流处理平台,从 Kafka 读数据,处理完再写回 Kafka,并且想要使用 EWS 把我的应用部署在云端大规模集群上;而另外小组表示我不需要那么复杂,我只是小规模数据,不希望起一个集群,只需起三个机器,并且每个机器有 1GB 内存足以,可进行手动控制操作,不需要资源管理器。那么我们能不能同时满足他们不同的需求呢? 答案就是我接下来要说的第三种选项。
第三种选项是使用一个轻量级流处理的库,而不需要使用一个广泛、复杂的框架或者平台来满足他们不同的需求。在 Kafka 0.10 当中已发布轻量级流处理内容平台,我们可以设想,跟其他客户端发布者和消费者一样,它也是一个客户端,不同之处在于它是一个计算者客户端,一个好用的、功能强大的客户端,并且支持 state processing、Windows 延时的、异步的、甚至不同数据的调控。 最重要的是 Kafka 作为一个库,可以采用多种方法来发布流处理平台的使用。比如,你可以构建一个集群;你可以把它作为一个手提电脑来使用;甚至还可以在黑莓上运行 Kafka。以上都是尤其简单的运行库的概念。

因此我们要做的事情与使用 Kafka 其他的客户端类似,比如发布者、消费者,只要在代码里边加入就可以使用各种各样的 API。当你要调配控制 Kafka Stream 应用的时候,选择最基础的 War File 来运行或者采用 Java、C,甚至资源管理器来运行都是可行的。因为 Kafka Stream 是一个轻量级流处理的库,可支持各种各样的运维方式。
在我们看来,简单的就是美的,只有给用户提供最大的兼容性与最大的延展性,用户才能得到最好的用户体验。
Kafka Stream 的编程语言

如果接触过 Storm、Spark 等流处理平台的同学可以发现,它们与 Kafka Stream 高阶位 DSL 语言其实有相似之处。如上图所示,首先定义一个 Streams 流, Streams 是从 topic1 中的 topic 获取得到,即定义 Streams、处理 Streams、得到新的 Streams。比如,从 topic1 里面得到两个原始数据流,然后数据流进行 countByKey 得到新的数据流叫做 Counts。那么 counts.to(“topic2”) 是什么意思呢?在获取到新的数据流之后写回 Kafka topic2 内,启动 KafkaStreams 进程,与 Kafka producer、Kafka consumer 类似,让它来运行已定义计算。

正如大家所了解的,API 的使用其实很简单。提供一个简单的 API,用户简单地写入运行逻辑即可运行。但是编程应用总是容易的,而它的复杂程度在于,一旦你开始运维该应用,当你想要把业务拓展到更大规模,或者业务出现变化,或者集群不稳定,需要强大的运维时,运维的程度便显得异常重要,最上面的编程可能只是冰山一角。Kafka Stream 的设计理念是最简单的就是最美的,包括 API、运维、debugging,以及各种各样的方式,都是希望给用户带来最简单的体验。它的核心思想就是把难问题直接给 Kafka 集群本身。
Kafka 的介绍
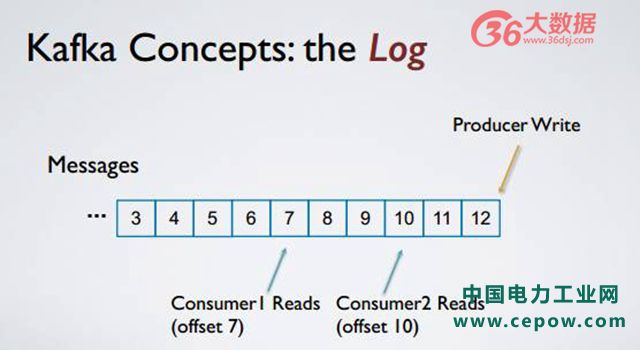
Kafka 的核心思想是什么?就是把这些消息全部存成一个有序日志,所有的消息发布者把消息发布到底端,从某一个逻辑上的位移开始顺序读取所有的消息。它的一个好处在于所有的读和写,尽管都是刷到磁盘上,但都是按照顺序进行,该方式对磁盘的使用比较有效,倘若消费者和发布者隔得比较近,将利用 page cash 直接读数据。