技术
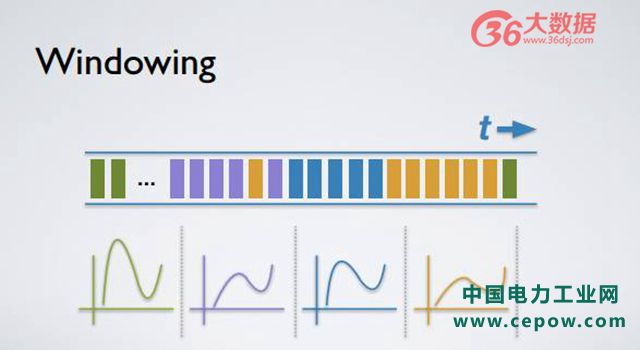
有如此时间戳,我们可以基于该时间戳进行各式计算,比方说 Windowing 的计算。举个例子,每隔 5 分钟计算一个平均值、总和或者合计,每一个 Windowing 正如上图颜色所示,不同颜色代表不同的时间戳和不同的 Windowing。当你收到一个 record,而该 record 时间戳指向非常未来的时间,你便得到一个非常未来的日志。Kafka 不会直接更新当前的 Windowing,而是会生成该时间戳所对应的 Windowing 更新 aggregate。
同理,倘若你继续计算,你会发现有个古老日志的时间戳指向很早以前的 Windowing。Kafka Stream 可以通过更新原本的 aggregate 来达到这样延时结果。用户在现在时间进行如下定义,比方说定义 Window aggregation,每一个 Windowing 是 5 分钟,但是我希望每个 Windowing 可保持整整一天时间,只要该 Windowing 在当前 24 小时之内依然存在即可做到。
写在最后
上文分享了较多内容,从 ordering 到状态、一直到 partitioning & scalability ,但其实最重要的是所有的这些都是由 Kafka Stream 库自动完成的。我们希望用户不要受到以上任何问题的影响,只需定义自己的业务,所有如上的问题都由 Kafka Stream 解决,尽管它只是一个库,但依然有足够强大的能力去处理所有事物。
我们在 Kafka 0.10 里面公布 Kafka Stream 之后,把 Streams 延展到 Java 以外的语言,比如支持 python,或者像 SQL 一样的更高阶编程模型来让用户更方便地定义自己的流处理应用。在 7 月份的 release 里面,我们也会增加正好一次(exactly-once)计算方式的 aggregate。
很多人可能会好奇,Kafka Stream 很好,可是我的数据原本不在 Kafka 内,而 Kafka Stream 只能从 Kafka 内部获取,如何将数据导入 Kafka 呢? 答案是 Kafka Connect,一个简单的数据导入导出框架。 时至去年年底,Kafka Connect 已经有 40 个不同规模的 Connect,包括从 JDBC 到 HDFS、一直到 MYSQL,以及所有可以想到的第三方系统,用户可以简单地把数据从第三方系统导入和导出 Kafka。
总之,回到本源,Kafka 到底是什么? Kafka 是一个中央式的流处理平台,他们支持消息的发布、消费、传输和存储,以及消息的计算和消息的处理。
以上是本文分享的全部内容。关注两个 Take-aways,第一个 Take-away,流处理只是不同的计算模型,它不会只给你近似的结果,只能用来做增量的结果;第二个 Take- away,因为 Kafka Stream 的存在使得 Stream processing 存在更加简单。