技术
当我们有多个并发流处理任务的时候,每个计算单元除了有一个自己的拓扑结构进行计算之外,也有一份 State Store。每个 State Strom 之间是存储完全不相干的流处理信息和数据。

接下来讨论的是 Kafka Streams 里面另一个重要概念,流与数据库表的关系?正如大家所看见的,在 Kafka Streams 内部有两种流—— KStream 与 Ktable,那么什么叫做 KStream?什么叫做 Ktable 呢?在开发 Kafka Streams 时的一个核心出发点是流和它所对应的表或者数据库的 State 彼此之间具有一一影射关系。为什么一一影射呢?
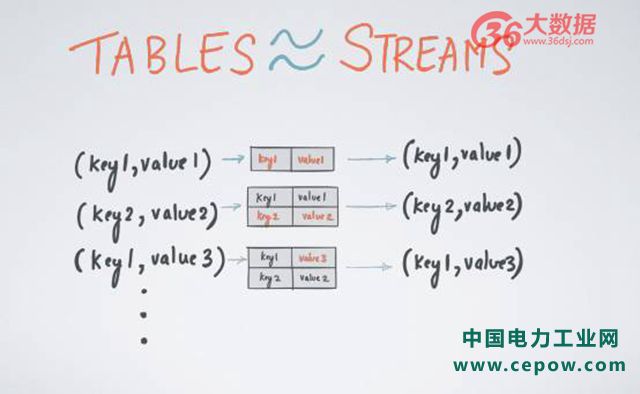
举个例子,假设你有一个上图的数据流,该数据流代表着某张表,即变量的日志或者更新日志。更新日志内含有 Key 和 Valve,比如第三条的更新日志(key1,value3)其实正在更新第 1 日志(key1,value1)的新信息,换句话说,原本 key1 所对应的是 value1,但是在这一时刻被改成对应 value3,如果我们重复更新该日志,我们能够得到什么呢?我们可以得到该表在任意时间段内的一个实时的可视化图。
同理,如果我们只有这样一个表,并且正在不断更新这个表,只要在每次更新时保留该日志,就能够从表反推回该更新日志的数据流所应的所有内容,这就是流和表或者流和状态之间的一一对应关系。总而言之,只要你有一个日志更新流,即可重构回你表状态在任意时间内的 value;如果你有一个表,也可以通过表的更新来找到该表所对应的流。这就是我所说的 A Stream is a changelog of a table ;A table is a materialized view at tiome of a stream. 流和表具有对应关系。
这促使我们定义两种不同的——KStream 和 KTable。KStream 是很普通的数据流,在数据流之间不存在任何因果关系和逻辑关系,可以被认为是 append only Stream。Typo 是更新日志流,每个日志里面相同的 key 所对应的就是对表的更新。那么为什么要定义这两种不同的数据流呢?我举个例子。
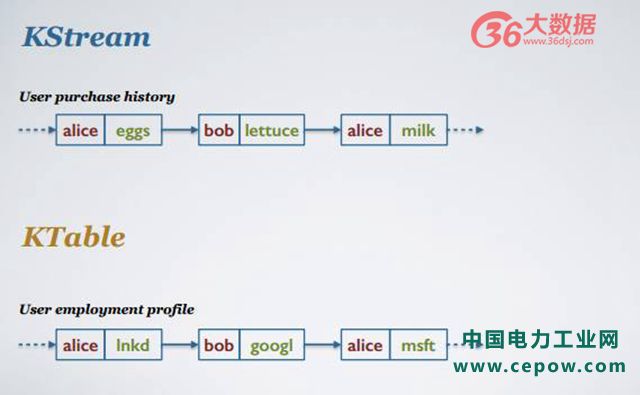
如上图,用户购买历史记录。比如 Alice 曾经买过鸡蛋和牛奶,鸡蛋和牛奶这两者之间不存在任何因果关系,Alice 买过牛奶只是在 Alice 买过鸡蛋上很简单的增量。用户雇佣状态的更新日志,比如 Alice 曾经在 LinkedIn 工作,之后信息被更新到 Alice 在微软工作,现在 Alice 在微软工作覆盖了之前的工作信息。
如果以当前的时间状态进行解读这两个流,第一个流显示的信息为 Alice 曾经买过鸡蛋,第二个流信息显示为 Alice 在 LinkedIn 工作。如果将时间往前推,查看更新的数据流信息可以发现,第一个 KStream 显示 Alice 买了鸡蛋又买了牛奶;但是在第二种情况下,Alice 并不是同时在 LinkedIn 和微软工作,而是 Alice 已经在微软工作,不在 LinkedIn 工作了。
为什么两种不同的流有两种定义呢?因为当你做相同操作的时候,比方说简单做一个合计操作,不同的流得出的结果是不一样的。在上者,如果我们将时间往前推,可得出 Alice 的合计结果是 2+3;但是在下面,如果对其进行 KTable 的 aggregate,显示 Alice 的结果是将其原本数值 2 变成 3,而不是 +3 的关系。