技术
在过去几年,对于 Apache Kafka 的使用范畴已经远不仅是分布式的消息系统:我们可以将每一次用户点击,每一个数据库更改,每一条日志的生成,都转化成实时的结构化数据流,更早的存储和分析它们,并从中获得价值。同时,越来越多的企业应用也开始从批处理数据平台向实时的流数据数据平台转移。本演讲将介绍最近 Apache Kafka 添加的一些系统架构,包括 Kafka Connect 和 Kafka Streams,并且描述一些如何使用它们的实际应用体验。
流处理
在流处理刚被提出来的时候,很多人认为流处理只能进行做近似的结果或者增量的计算,倘若你想保证其安全性,以 Lamda 架构为基础,利用流处理得到最现在的结果。但同时你需要采用 batch processing 等其他方式来保证其全局的安全性以正确性。
在如此多年的研究结果下,在我看来,流处理并不一定是近似的,或者是仅仅以无法保证真确性为代价而提高速度的一种数据处理方式。相反,流处理应该是一个与全局计算、batch processing 稍微有点不同的计算模型。跟批量处理不同之处在于,批量处理将数据引向计算,而流处理将计算引向数据。这句话大概有点模糊,接下来,我举几个大家熟悉的计算模型例子。
第一个计算模型例子—请求应答模型。

请求应答模型是业务生活中最常用的模型例子。首先提交一个请求到服务方,而服务方可能是一个数据库、也可能是别的存储工具;然后进行等待…等待;最后得到一个回答。这便是一次请求、一次计算、一次回答。该模型非常简单、也极易操作,当你需要延展到多个机器上时,只要简单地增加客户端以及处理器即可成功。但是缺点在于,不能达到大的吞吐量,每提交一次请求,都需要等待时间来获得最终应答的结果。

第二种常见的模型就是批量处理如上图所示。如果请求应答模型在谱系的一端,那么 typo 的另一端则认为是批量处理。当我积累数据数量足够多的时候,一次性提交任务到数据仓库,再进行等待,等待时间短则几秒钟、几分钟,长则几小时,最后才得到最终的结果—所有输入对应的所有输出。该批处理模型的好处在于能够提高其吞吐率,一次的请求和应答可以得出较多结果。但它的缺点是具有高延时性,比如某数据产生时间为上午 6 点钟,用户点击某网页,由于批处理模型,每 12 小时才会运行一次,那么它必须等到上午 6 点到下午 6 点的所有数据完整以后才会进行工作,那么运行结果可能是用户点击的 12 个小时之后。高延迟性是批处理自身带有的特性。
那么什么是流处理呢? 在我看来,流处理就是介于请求应答和批处理之间的一种新型计算模型或者编程模型。流处理并不等待数据的完整性,或者说数据本没有完整性这一讲法,数据本身就是一个数据流,当每个数据流每产生一个新数据的时候立刻被计算出、进行返回,因此数据是源源不断地通向计算,并且源源不断有结果被输出。你可以设想,与等待数据完全完成之后发布到计算上相比,流处理就是将计算移到你数据发生地进行实时计算的方式。
为什么很多人之前有这样一种错觉,他们认为流处理可能存在有丢包的情况、或者说只可以得到近似的结果,其实这是早期的一些数据流处理系统所自带的一些限制。因此以 Lamda 架构为基础,在流处理上需要讨论不同维度的取舍。接下里我将举三个例子,延迟、、成本和正确性。正如很多人之前提及的,在进行流处理时候,其大多数情况需要用时间来换取正确性,或者用更多的成本换取时间等等。
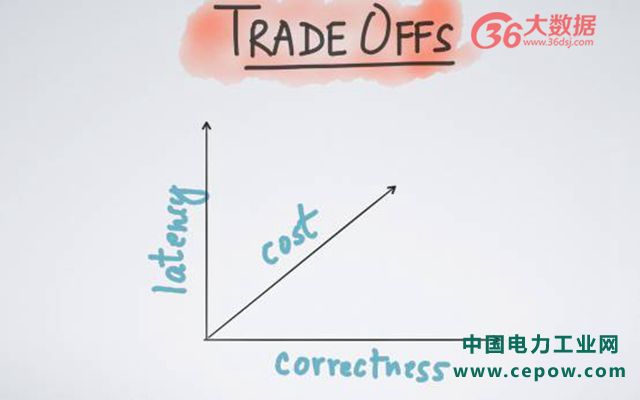
第一个例子,说如果你需要做一个实时的 ETL 处理。而关于 ETL 处理不需要太小的延迟,为达到低成本的一种保证,我们可以忍受几分钟或者 1 分钟的延迟;但是,如果你正在进行一个实时的在线监测,存在着几毫秒的延迟,那么这时候可能更愿意选择花大量的金钱,或者采取一些可能不必要的 possibility 来达到一种低延迟的效果;第二个例子,假设你在做一个在线付费协议,它也是一个流处理平台。由于在线付费协议可能关乎到其机构,或者其公司的利益所在,因此你会说,我需要保证百分之百的正确性,我不希望有任何丢包情况;