技术
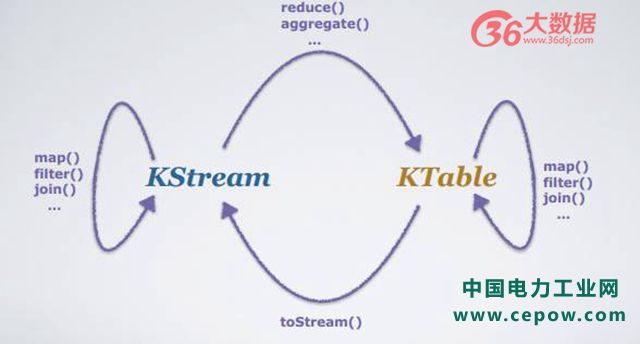
在 Kafka Stream 的 DSL 里面有多种不同的 aggregate,reduce 操作等, 不同的数据流可能将 KStream 变成 KTable,也可能把 KTable 变回 KStream,在用户定义如下不同的 operation 的时候,在后台不同状态的流可采用不同计算方式、计算模型。
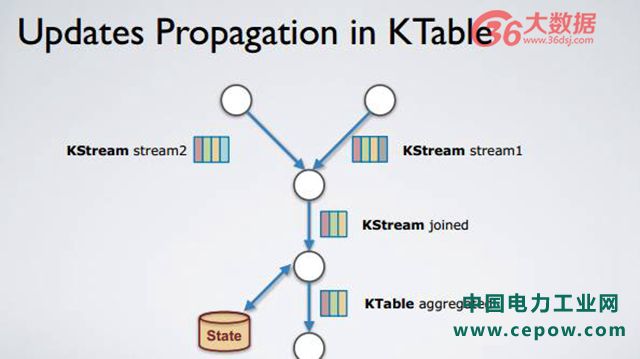
如上图,KTable。当一条新消息进来时该如何进行拓扑计算呢?举个例子,在该拓扑结构内,Stream2 出现了一个新的 record,即红颜色标记,该标记与第一条 record 颜色相近,因为它们是同个 key,不同 value。Stream2 和 Stream1 进行 join 操作成为一个新的 record,该新 record 会被放入到 KStream joined 里面,然后 KStream joined 进行 aggregate 操作,而 aggregate 操作得到的结果是 state 被更新,新 record 被 append 到 aggregate 流内,但是 append 操作将之前的红颜色 record 复写了,换句话说,因为有了该新 record 的存在,之前红颜色的 record 由于被复写已经不重要了。
Kafka Stream 运维
如果我们有一个 fault,那么我们如何在 Kafka Stream 上做 fault tolerance?
正如上文所提及的,Tables 和 Stream 之间存在一一影射关系,Kafka Stream 有效地利用了该特性。举个例子,有个 Kafka Stream 的应用业务,该业务有三个并发 task,每个 task 有自己的 local state,每当 State 进行更新时,Kafka Stream 就会自动将更新消息写到更新日志内,更新日志也自动生成。每更新一个状态时,消息日志就被更新该日志上。
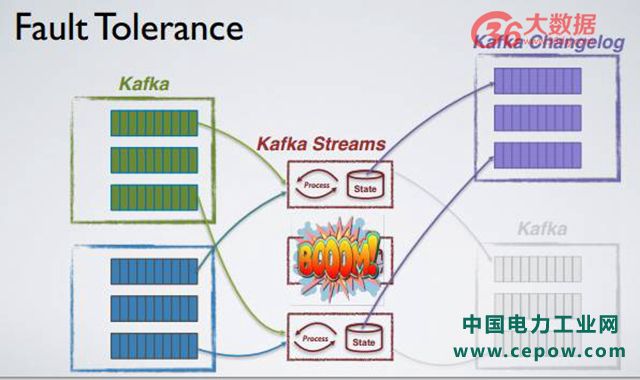
比如过了一段时间,中间的 task 坏掉了,那么 Kafka Stream 会做什么呢?首先它会检测异常,自动地在已有的 instance 上重新启动原本坏掉的 task,重新构建 State,那么 State 怎么 build 呢?通过更新 changelog,直到 restore 整个原本正在进行的状态的 restoration,只有新状态被 restore 完整之后才能继续 task 同步计算。
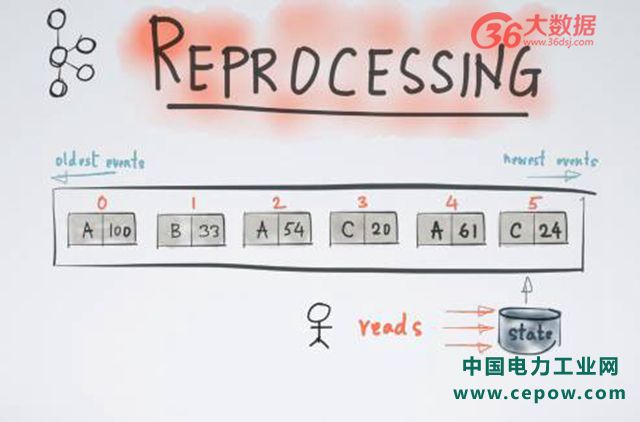
消息回溯也是类似的原理。比方说,某应用已被运行了很多年,发现 stream 流处理计算里面存在 Bug,我们不得不将已计算的结果舍弃,回溯到一个更早的历史时间重新进行计算,即计算回溯。Reprocessing 在 Kafka Stream 也是一种简单的方式,当我们达到某一个位移,比如位移 5,需要进行消息回溯时,用户可以简单地起一个新的状态 -New State,该 State 完全没有任何内容,然后从最早的时间开始重新进行计算,直到计算到赶上现有 task 时候。只需要 switch over 就可以完成消息回溯,且该整个消息回溯过程不需要关闭整个流处理任务。于是很多人便问,那么 Kafka Stream 能不能支持 Streaming processing 呢?
举个例子,我不希望 Kafka Stream 一直在运行,希望它可以每 6 个小时 run 一次,并且每 run 一次可将当前所有已累计的 Kafka massage 全部处理掉。这个操作也很简单,从 outsite A 开始,一直位移到 B 结束或者到 C 结束,表示已停止整个应用;6 个小时之后当它重启的时候,再从新的位移开始进行下一段的位移,这是批处理计算结果,即从一个 outsite 到另外一个 outsite,紧接着是另外一个 outsite…Kafka Stream 通过位移的控制和管理进行批处理结果,而不需要运行整个 Kafka Stream。
时间的管理
时间管理是流处理上非常重要的观念,同时也是区别于流处理和批量式处理非常重要的概念。很多人都已熟悉 Event Time 和 Processing Time 的区别,Event Time 是每个日志、消息、状态发生的时候所发生的时间,而 Processing Time 是日志被计算和处理的时候所发生的时间。这两者可能并不是完全融合的,可能存在位移,这便是所谓的时间延迟。

如上图,以《星球大战》故事时间和拍摄时间为例。《星球大战》有七步曲,Processing Time 是电影真正拍摄时间,是在现实生活中的时间——1999 年到 2015 年;但是拍摄时间和星球大战所发生时间并不一一对应,存在延迟。对其做流处理时候可以发现,类似 out of order 的现象很常见,比如因为数据量太大而导致数据发生延迟,或者说数据处理发生了延迟等,都会发生延时情况。
那么 Kafka Stream 怎么解决该问题呢? Kafka Stream 允许给每个日志定义时间戳,该时间戳可以是当前系统时间,也可以是提取时间戳,也可以从当前 record 被生成的时候所提取的时间戳,这些即被定义成 Event Time。类似的,如果 record 是一个 Jason format,将其时间戳提取出来也可被定义成 Event Time。