技术
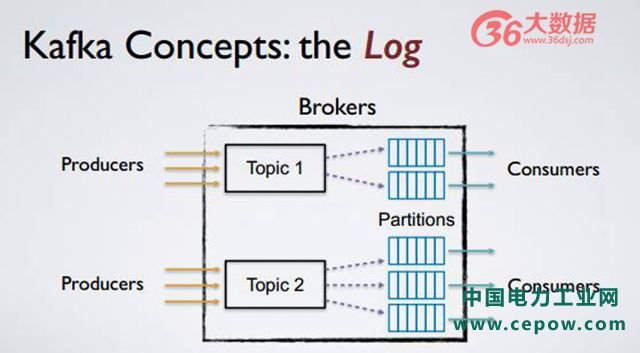
延展性。如上图,提供 topic 以及 topic partitions,即话题与话题分区的机制。每个用户有不同的 topic,每个 topic 可以有多个分区,每个分区可被装载在不同的机器上,当用户提高规模之后,Kafka 只需要简单地增加机器和 topic partitions 数量,或者采用 ROM balance 的方式到不同机器上,即可达到线性延展方式。
以上是 Kafka 最简单的核心思想,接下来我将介绍 Kafka Streams 作为 Kafka 客户端如何利用以上核心思想来设计流处理的平台。数据流其实就是有序的记录或消息,每个消息是一个 Key 加一个 Value,并且 record 与 Kafka 自身 massage 具有一一对应关系。

用户所提供的业务上的计算模型,其实可用拓补结构进行表达。如上图,图的左边。用户首先进行定义数据流,然后对数据流进行计算,得到新的数据流,最终将数据流写回到 Kafka 内。每当用户进行定义的时候,每一步都会变成拓扑结构里面的一个点,每个点通过流进行计算,变成新的流来进行新的连接,最终在 Kafka 内部形成拓扑结构。用户并不需要在意该拓补结构,只需明白定义流、计算流、得到新的流,写回 Kafka。
连接每一个不同的运算单元就是一个 Stream,即 record stream,每一个 Stream 都在源源不断地实时产生 record,每一个 record 是一个 key 加一个 value。利用 Stream Processor 连接 Stream,每个用户定义的流的一个计算单位对应着一个 Stream Processor。
当用户定义每一步计算的时候,就是定义每个拓扑结构里面的每个点,最终把整个拓补结构定义完整到 Kafka Stream 来运行。计算单元其实可分成两个特殊的单元,一个叫做元的计算单元,只有输出流,没有输入流,它们唯一的认同就是从 Kafka 读取数据形成数据流,传递给下方其他数据处理。而 Stream Processor 底端的数据流,没有输出流,只有输入流,它们的功能是把所有输入流写回到 Kafka。Kafka 的运行操作简单,源数据从 Kafka log 读取消息变成数据流,每个消息贯穿整个拓扑结构,最终从 Stream Processor 写回到 Kafka。以上为 Kafka Stream 运行情况。
用户进行并行发布进程、应用或者多个计算的操作其实也非常简单。Kafka 是一个库,当你用 Kafka 库写成应用,当 record 写入多台机器时,Kafka Stream 库本身就会自动调动 partitions 方式,假设你有两台机器,每台机器上都运行了 Kafka Streams,当它同时进行运行时,不同的 streams application instance 就会从不同的 Kafka partitions 内读取数据来达到并行任务的分发与执行,任务之间没有任何的数据重叠,当你需要更多线性地增长任务时,你只需要在不同的机器上运行同样的 record,所有的 instance 将会自动进行 rebalance,把新的 application 写入,然后获取到延展。
很多人看到不同的计算方式的时候会发现,有的计算方式,比如说 fliter、map,没有“计算状态”需要保存,一个数据进来计算、一个数据出去。但是有的计算,比如说 join、aggregate,就需要动态维护一个“计算状态”,每一次新的信息或者日志进来的时候, Stream 就要进行更新甚至进行读取。后者被称为 Stateful Processing,前者为 Stateless Processing。
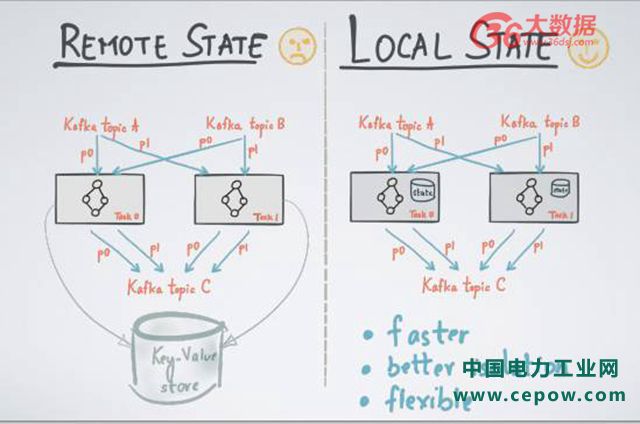
那么如何进行管理流处理的 states 呢?有两个通用的方式,一个方式是 remote State,利用远程的数据库或者远程的 key value store 存储所有流处理的 states,每一次计算的时候,发送一个远程请求来读取 states。远程请求的缺点在于需要进行远程的请求和应答。因为 states 存在于 Remove State 上,states 之间可能会有 overlation,不能很好做到 accesstion. 比如我是团队 A,只负责 sell,另外一个是团队 B,只负责 ajustment, 两个不同的流有着不同的 job,但是 state 存在一起,所以两者会相互影响;
另外一个方式是 Local State,意味着所有的 state 和所有的处理单元是并发在一起的,每个单元上存着 state。在 Kafka Stream 里面,每个计算单元之间不需要有任何交互,state 之间亦如此。我们只要把 state 存到 Local 计算单元上就足矣。第一,可以保证 better isolation,它们之间没有任何的 access;第二,local state 可以做到更好的时效性,不需要远程读写。

如上图,在 Kafka 内有 aggregateByKey(…)语句,类似于 Stateful Processing。当用户定义 Stateful Processing 的时候,在 Kafka Stream 库内部就会自动生成 State Strom,且与 aggregate opprate 进行连接,只有该 opprate 能够对该 State Strom 进行读写,因为每个 opprate 有自己独有的 State Strom,可达到 State Strom 完全 Local 化。